
DNS는 단순히 "도메인 이름을 IP 주소로 바꿔주는 시스템."으로 불리고 틀린 말은 아니다. 실제로 DNS는 이 역할에서 출발했다. 사람이 기억하기 IP주소를 대신해, 읽기 쉬운 이름을 사용하게 해주는 일종의 전화번호부였다.

하지만 지금의 DNS를 이 정도로 이해하고 있다면, 현실과는 꽤 거리가 있다. 현대의 웹 환경에서 DNS는 단순한 조회 시스템이 아니다. 사용자가 페이지를 열기까지의 첫 번째 네트워크 관문이자, 그 이후에 이어지는 모든 과정의 속도를 결정짓는 출발점에 가깝다.
새로운 연결이 필요한 경우 브라우저는 일반적으로 DNS 조회를 거쳐야 한다. 이 단계가 지연되면 TCP 연결도, TLS 핸드셰이크도, HTTP 요청도 모두 뒤로 밀린다. 즉, DNS가 느리면 나머지가 아무리 빨라도 전체는 느릴 수밖에 없다.
문제는 여기서 끝나지 않는다. 오늘날 DNS는 단순히 "어디로 갈지"만 알려주지 않는다. 사용자의 위치에 따라 가장 가까운 서버를 선택하고, 어떤 프로토콜로 연결할지 결정하며,심지어는 보안 설정과 프라이버시 수준까지 간접적으로 좌우한다. 이제 DNS는 단순한 인프라 구성 요소가 아니라,성능, 보안, 그리고 사용자 경험을 동시에 좌우하는 핵심 레이어다.
이번 포스팅에서는 DNS를 더 이상 '주소 변환'으로 보지 않고 브라우저 렌더링 성능, 네트워크 병목, 그리고 런타임 이슈까지 이어지는하나의 연결된 흐름으로 바라보려고 한다. DNS를 이해한다는 것은 , 웹 애플리케이션이 느려지는 이유를 가장 앞단에서 설명할 수 있게 된다는 뜻이다.
왜 DNS는 생각보다 느릴까?
DNS는 보통 "빠르다"는 전제를 깔고 이야기된다. 실제로 대부분의 경우, 우리는 DNS의 존재를 거의 느끼지 못한다. 하지만 이건 어디까지나 캐시가 잘 동작하고 있을 때의 이야기다.
브라우저가 이미 해당 도메인의 IP를 기억하고 있거나,운영체제 또는 ISP 리졸버 어딘가에 캐시가 남아 있다면 DNS 조회는 몇 밀리초 안에 끝나버린다. 문제는 이 캐시가 한 번이라도 빗나가는 순간부터 시작된다. 처음 방문하는 도메인이거나,TTL이 만료되어 캐시가 비워진 상태라면,브라우저는 직접 답을 찾을 수 없기 때문에 외부 네트워크에 질의를 던져야 한다.
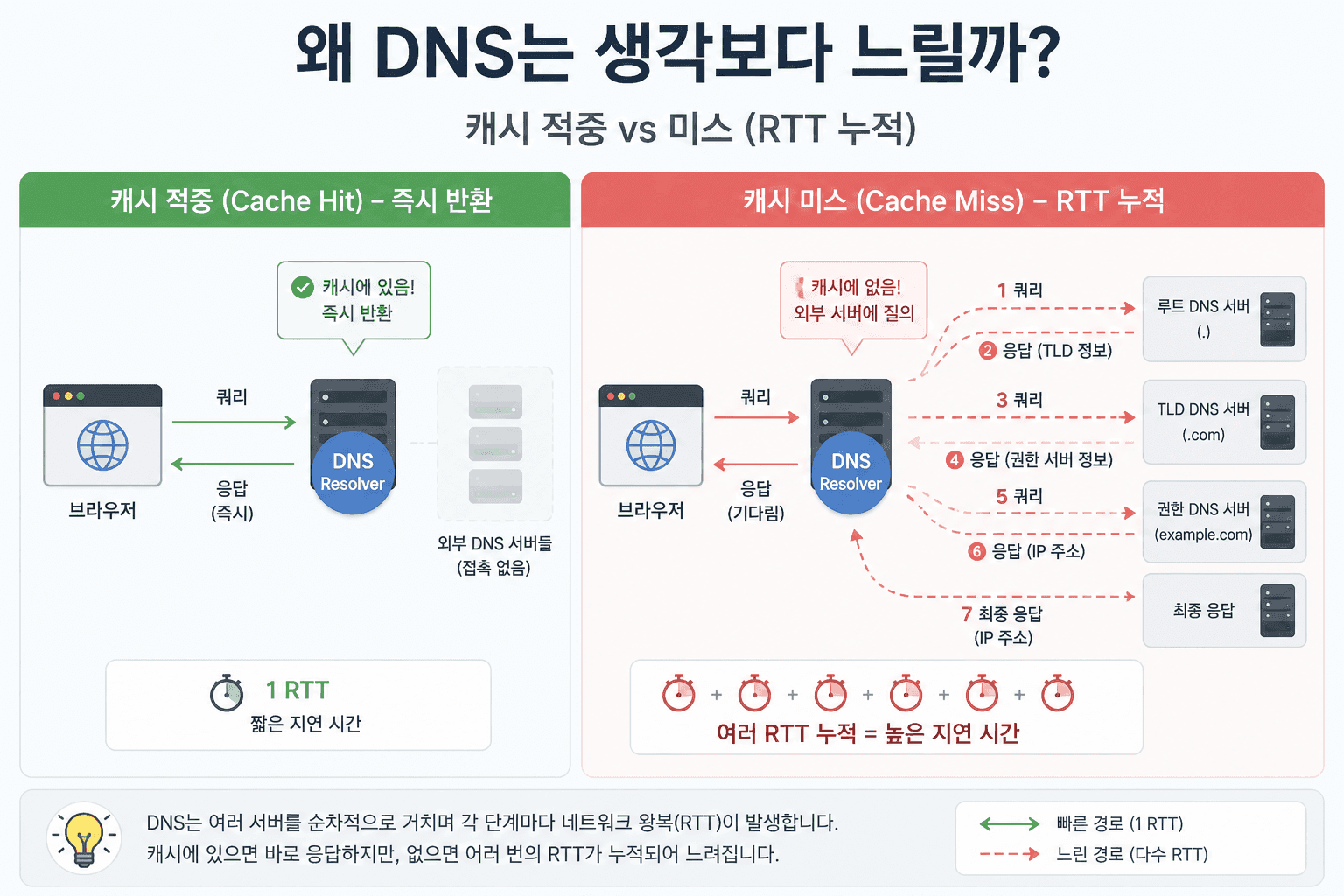
이때 DNS 조회는 단순한 "한 번의 요청"이 아니다.리졸버는 루트 네임서버를 시작으로,TLD 서버를 거쳐,최종적으로 권한 있는 네임서버까지 단계적으로 탐색을 진행한다.각 단계마다 네트워크 왕복(RTT)이 발생하고,이 지연이 누적되면서 수십에서 수백 밀리초까지 쉽게 늘어난다.겉보기에는 단순한 "주소 조회"지만,실제로는 여러 서버를 거쳐 답을 찾아오는 분산 탐색 과정인 셈이다.
더 중요한 사실은 이 지연이 항상 가장 앞에서 발생한다는 점이다. DNS 조회가 끝나기 전에는TCP 연결도 시작할 수 없고,TLS 협상도 진행되지 않으며,HTTP 요청 역시 전송되지 않는다. 즉, DNS는 전체 네트워크 파이프라인의 입구에서모든 것을 멈춰 세울 수 있는 구조를 가지고 있다. 그래서 DNS는 "작은 비용"처럼 보이지만,실제로는 페이지 로딩 성능을 결정짓는 첫 번째 병목이 된다.
브라우저에서 시작되는 DNS 조회의 전체 흐름
사용자가 브라우저 주소창에 example.com을 입력하는 순간,브라우저는 바로 서버로 요청을 보내지 않는다. 가장 먼저 해야 할 일은 단 하나다."이 도메인의 IP 주소가 무엇인지 알아내는 것"이다. 이 과정을 DNS 조회라고 부른다. 겉보기에는 단순한 질문처럼 보이지만,브라우저는 이 답을 얻기 위해 여러 단계를 거친다.
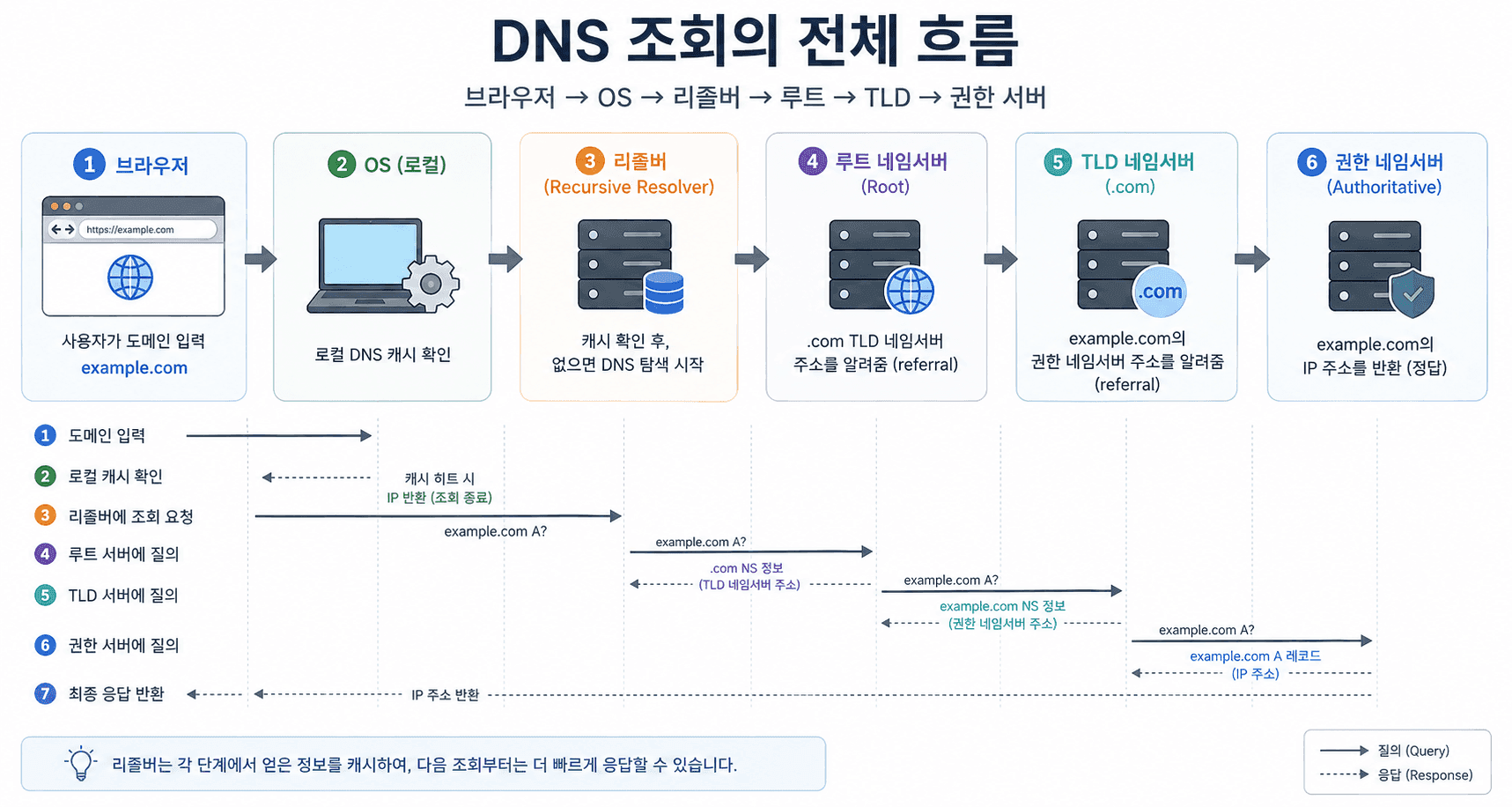
1. 브라우저 캐시 확인
가장 먼저 브라우저는 스스로에게 묻는다.
"이 도메인, 전에 이미 조회한 적 있지 않았나?"
만약 이전에 방문한 기록이 있고, 캐시가 아직 유효하다면여기서 바로 IP를 꺼내 쓰고 과정은 끝난다. 이 경우 DNS 조회는 사실상 0ms에 가깝게 끝난다.
2. 운영체제(OS) 캐시 확인
브라우저 캐시에 없다면,이제 운영체제에게 요청을 넘긴다. 운영체제 역시 DNS 캐시를 가지고 있기 때문에,다른 애플리케이션이 과거에 조회했던 기록을 공유할 수 있다. 여기서도 답을 찾으면 외부 네트워크로 나갈 필요 없이 종료된다.
3. 리졸버(Resolver)에게 질의
브라우저와 OS 모두 답을 모른다면,그때 처음으로 외부 네트워크가 등장한다. 운영체제는 설정된 DNS 서버(보통 ISP나 8.8.8.8 같은 퍼블릭 리졸버)에게 질문을 보낸다.
"example.com의 IP 주소를 알려줘"
이 리졸버는 대신해서 답을 찾아주는 역할을 한다.
4. 루트 → TLD → 권한 서버로 이어지는 탐색
리졸버도 캐시에 답이 없다면,이제 본격적인 "탐색"이 시작된다. 이 과정이 DNS를 이해하는 핵심이다.
- 루트 서버에 질문→ ".com은 어디에 물어봐야 해?"
- TLD 서버(.com)에 질문→ "example.com은 어디가 관리해?"
- 권한 있는 네임서버에 질문→ "example.com의 IP는 뭐야?"
이렇게 위에서 아래로 내려가며 답을 찾아간다. 중요한 점은,각 단계가 모두 별도의 네트워크 요청이라는 것이다.
5. 결과 반환 (그리고 캐싱)
최종적으로 IP 주소를 알아내면,이 정보는 다시 클라이언트에게 전달된다. 그리고 동시에 리졸버, 운영체제, 브라우저 각 계층에 모두 캐시로 저장된다. 덕분에 같은 도메인에 대한 다음 요청은 이 긴 과정을 다시 반복하지 않아도 된다. 결과적으로 DNS 조회는 단순한 "한 번의 요청"이 아니다.
브라우저 → OS → 리졸버 → 루트 → TLD → 권한 서버로 이어지는 단계적인 탐색 과정이다. 그리고 이 과정 중 단 한 단계라도 캐시가 없다면, 실제 네트워크 왕복이 발생하면서 지연이 누적된다. 이 구조 때문에 DNS는평소에는 거의 느껴지지 않지만, 캐시가 깨지는 순간 갑자기 느려지는 특성을 가진다.
DNS 계층 구조
DNS는 하나의 거대한 서버가 모든 도메인을 관리하는 구조가 아니다.대신, 전 세계에 분산된 서버들이 역할을 나눠 갖는 계층 구조로 이루어져 있다.
이 구조를 이해하는 가장 쉬운 방법은 "누가 어떤 정보를 알고 있는가"를 기준으로 보는 것이다.
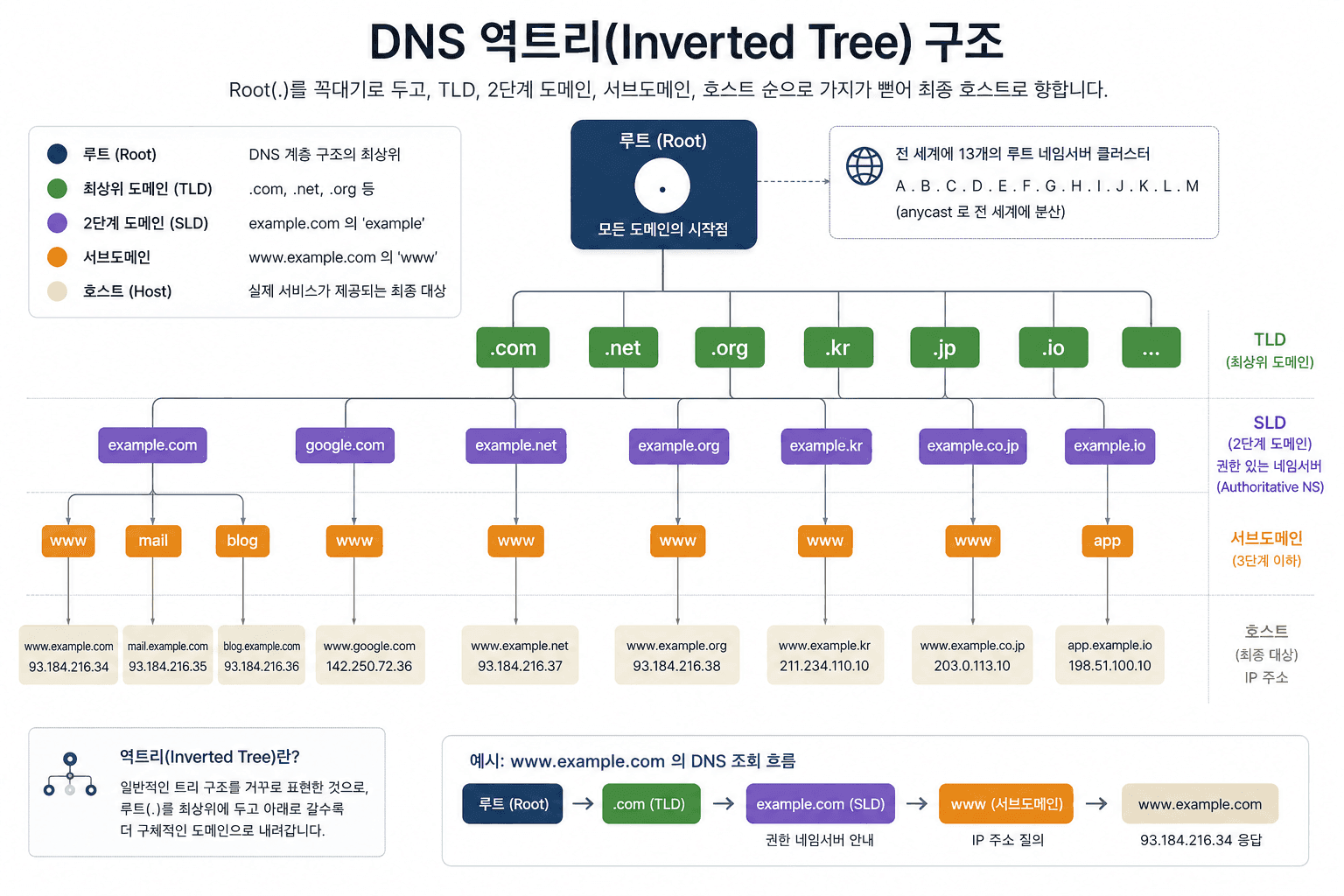
1. 루트 서버: 시작점
DNS 탐색은 항상 루트 서버에서 출발한다. 루트 서버는 특정 도메인의 IP를 직접 알고 있지는 않지만,대신 이렇게 답한다.
".com 도메인은 이쪽에 물어봐"
즉, 다음 단계로 어디를 가야 하는지 알려주는 역할이다.
2. TLD 서버: 도메인 종류 담당
그 다음은 TLD(Top-Level Domain) 서버다..com, .net, .kr 같은 도메인 확장자를 관리한다. 여기서도 아직 최종 IP는 나오지 않는다. 대신 이렇게 이어진다.
"example.com은 이 네임서버가 관리해"
즉, 해당 도메인의 담당자를 찾아주는 단계다.
3. 권한 있는 네임서버: 최종 답변
마지막 단계가 바로 권한 있는 네임서버(Authoritative Name Server)다. 여기에는 실제 DNS 레코드가 저장되어 있다.
- example.com → 93.184.216.34
이 서버만이 "이 도메인의 실제 IP는 이것이다"라고 확정적으로 답할 수 있다.
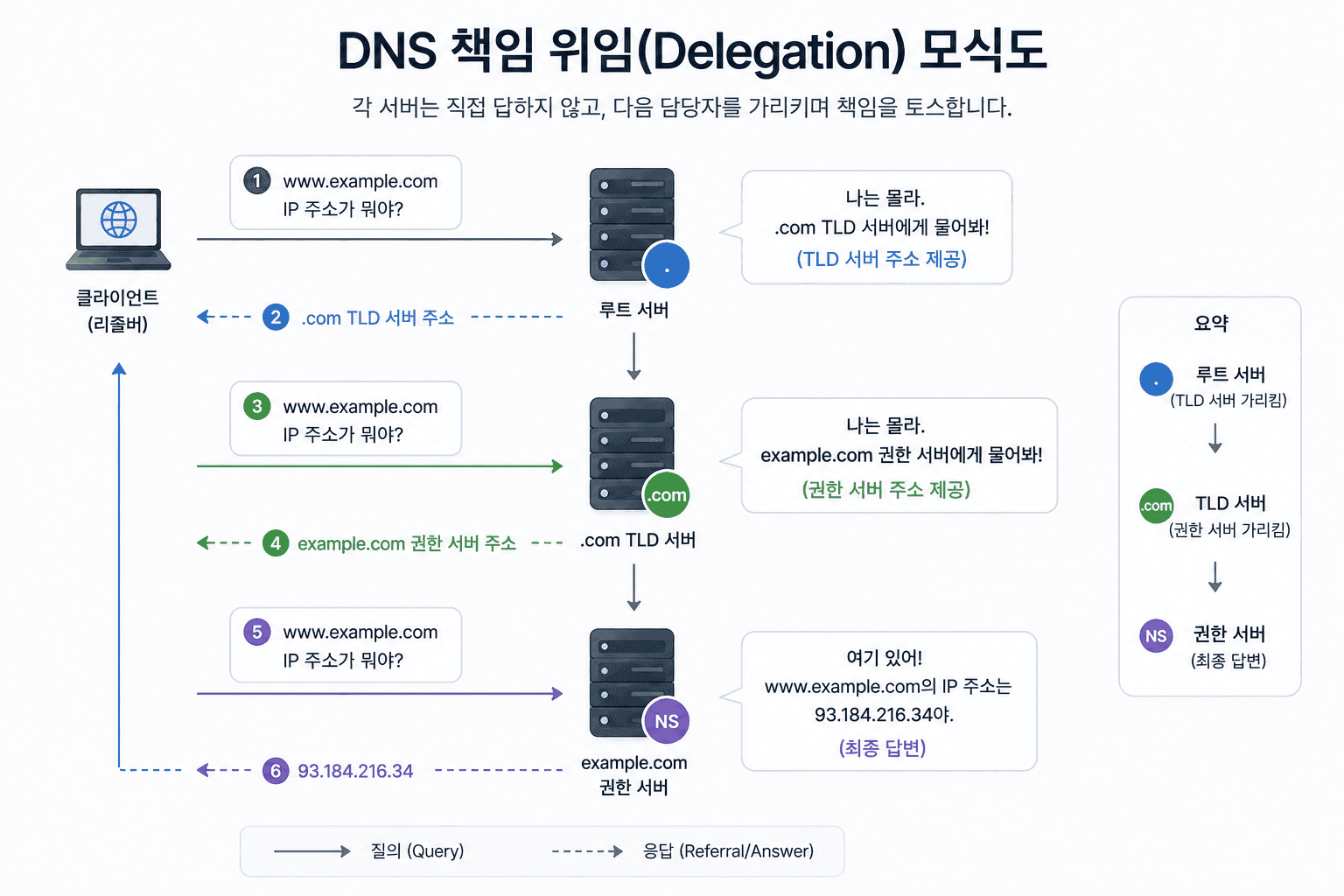
왜 이렇게 복잡하게 나뉘어 있을까?
이 구조는 단순한 설계 취향이 아니라,인터넷의 규모 때문에 필수적인 선택이다. 만약 하나의 서버가 모든 도메인을 관리한다면트래픽은 감당할 수 없고,단 하나의 장애로 전체 인터넷이 멈출 수도 있다.
DNS는 이 문제를 해결하기 위해 책임을 아래로 위임하는 구조를 선택했다.
- 루트는 방향만 알려주고 (어디로 가야 하는지 알려줌)
- TLD는 담당자를 연결해주고 (누가 관리하는지 알려줌)
- 최종 데이터는 각 도메인의 네임서버가 직접 관리한다. (실제 답을 제공함)
이 덕분에 인터넷은 수십억 개의 도메인을 안정적으로 처리할 수 있게 되었다. 이 흐름을 이해하면, DNS 조회가 왜 여러 단계를 거치는지 자연스럽게 이해할 수 있다.
꼭 알아야 할 DNS 레코드 (A, CNAME, ALIAS)
DNS 조회의 최종 결과는 단순하다.결국 브라우저가 원하는 건 하나다.
"이 도메인의 IP 주소는 무엇인가?"
이때 사용되는 정보가 바로 DNS 레코드다. 실무에서 자주 마주치는 레코드는 많지만, 웹 서비스를 운영하는 입장에서 핵심은 세 가지만 이해하면 충분하다.
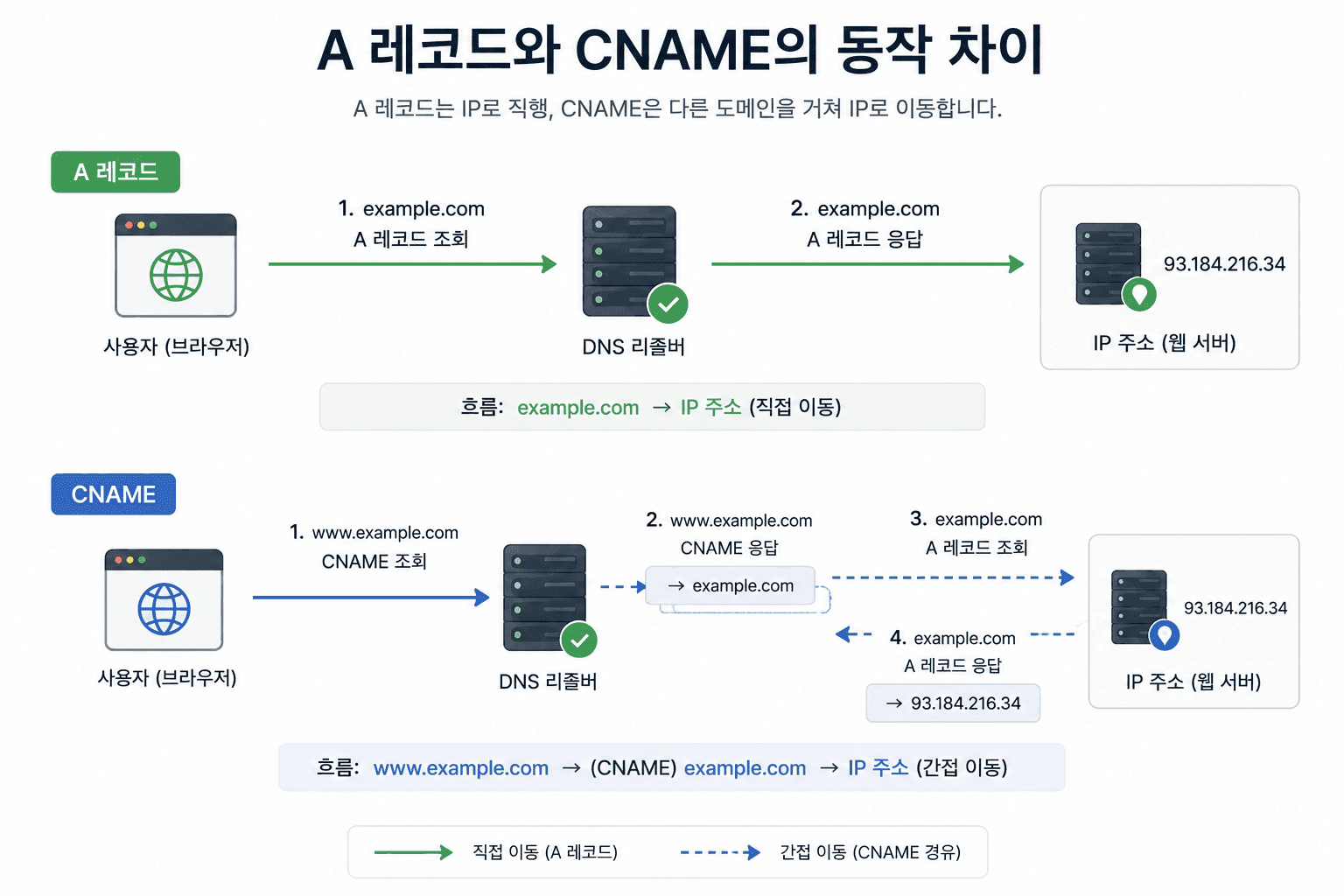
1. A 레코드: 가장 기본적인 연결
A 레코드는 도메인을 IP 주소에 직접 연결한다. 예를 들어 아래처럼
- example.com → 93.184.216.34
가장 단순하고 직관적인 방식이다. 브라우저는 이 값을 받아 바로 서버로 연결을 시도한다. 주로 "고정된 서버 주소로 바로 연결할 때" 사용된다.
2. CNAME: 도메인을 다른 도메인으로 연결
CNAME은 IP가 아니라,다른 도메인을 가리키는 별칭이다. 예를 들어 아래처럼
- www.example.com → example.com
- images.example.com → cdn.provider.com
이 경우 브라우저는 한 번 더 DNS 조회를 통해최종 IP를 알아낸다. 주로 "CDN이나 외부 서비스에 연결할 때 " 사용된다.
3. ALIAS: 루트 도메인의 한계를 해결하기 위한 선택
여기서 한 가지 문제가 생긴다. DNS 표준상, 루트 도메인(example.com)에는CNAME을 설정할 수 없다. 하지만 실제 서비스에서는루트 도메인을 CDN이나 로드밸런서에 연결해야 하는 경우가 많다.
이 문제를 해결하기 위해 등장한 것이 ALIAS 레코드다. ALIAS는 표준 DNS 레코드는 아니며, 일부 DNS 제공업체가 루트 도메인에서 CNAME과 유사한 동작을 지원하기 위해 제공하는 확장 기능이다. ALIAS는 내부적으로는 CNAME처럼 동작하지만, 외부에는 최종 IP(A 레코드 형태)를 반환한다. 주로 "루트 도메인을 CDN에 연결해야 할 때" 사용된다.
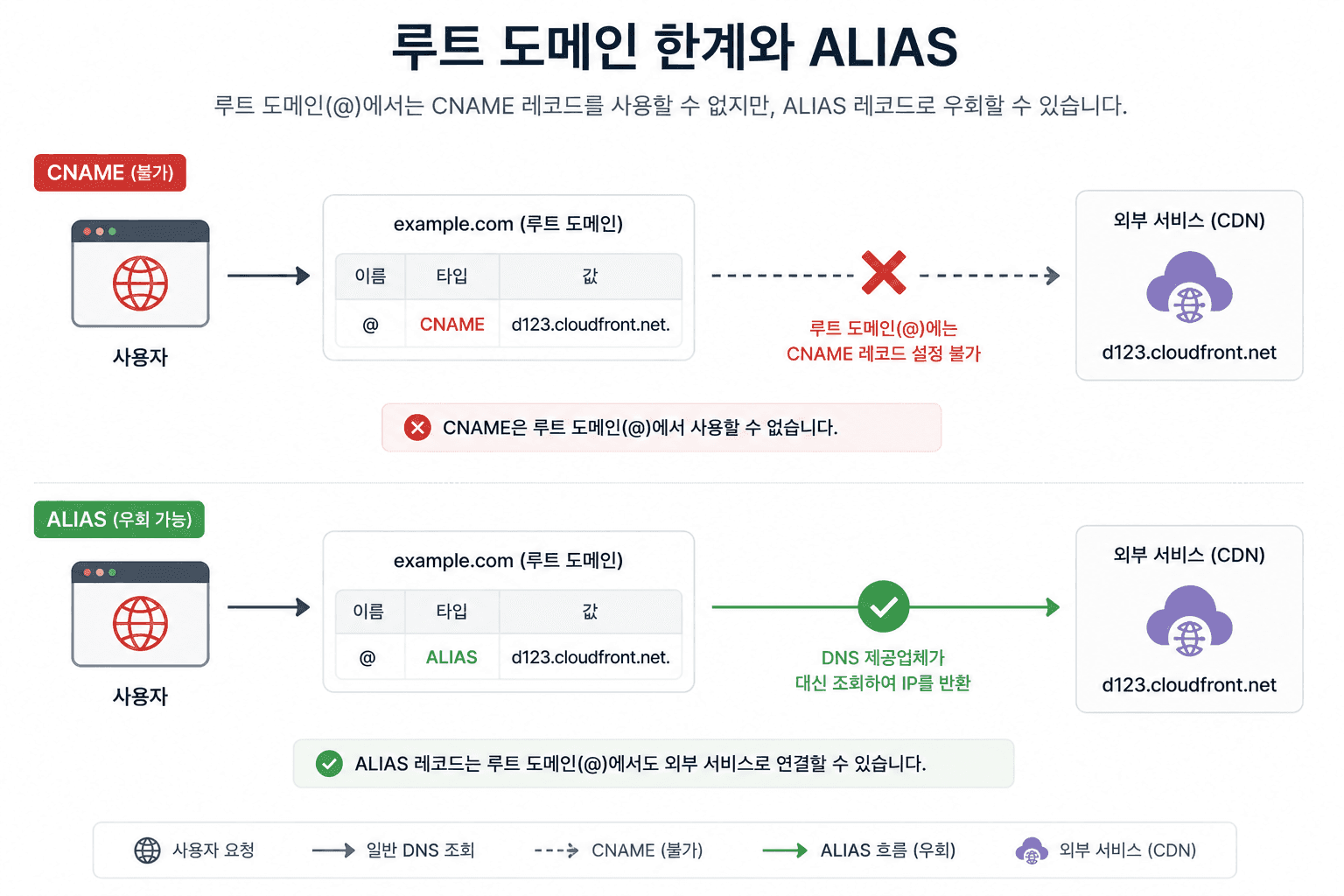
왜 이게 중요할까? 현대 웹 서비스는 하나의 서버에 고정된 구조가 아니다.
- CDN, 로드 밸런서, 클라우드 인프라
이 모든 시스템은 IP가 계속 바뀔 수 있다. 그래서 단순한 A 레코드만으로는 부족하고, CNAME이나 ALIAS를 통해 유연하게 연결하는 구조가 필요해진다.
- A: 도메인 → IP 직접 연결
- CNAME: 도메인 → 다른 도메인
- ALIAS: 루트 도메인에서도 CNAME처럼 사용 가능
이 세 가지를 이해하면 대부분의 DNS 설정과 인프라 연결을 설명할 수 있다.
DNS 캐시는 어디까지 존재할까?
DNS는 생각보다 자주 바뀌지 않는다. 그래서 매번 네트워크를 통해 조회하는 대신,여러 단계에서 결과를 저장해 두는 캐시 구조를 사용한다. 이 캐시는 단순히 한 곳에만 있는 게 아니라, 여러 계층에 나뉘어 존재한다. 그리고 이 구조 때문에 개발자들이 자주 겪는 이상한 상황이 발생한다.
"나는 되는데, 다른 사람은 안 된다"
1. 브라우저 캐시
가장 앞단에는 브라우저 캐시가 있다. 크롬이나 사파리 같은 브라우저는자체적으로 DNS 결과를 메모리에 저장한다. 같은 탭이나 세션에서 반복 요청이 발생하면운영체제를 거치지 않고 바로 IP를 사용한다. 가장 빠르지만, 범위는 브라우저 내부로 제한되는 특징이 있다.
2. 운영체제(OS) 캐시
브라우저에 없으면,다음은 운영체제의 DNS 캐시를 확인한다. 이 캐시는 시스템 전체에서 공유된다. 즉, 브라우저나 터미널 혹은 다른 애플리케이션 모두 같은 결과를 재사용할 수 있다. "왜 브라우저를 껐다 켜도 계속 같은 결과가 나오지?"→ OS 캐시 때문인 경우가 많다.
3. 리졸버 캐시 (ISP / Public DNS)
로컬에서도 답을 못 찾으면,외부의 DNS 리졸버에게 요청이 간다. 이 리졸버 역시 강력한 캐시를 가지고 있다.
- ISP DNS, Google (8.8.8.8), Cloudflare (1.1.1.1)
이 서버들은 전 세계 사용자의 요청을 처리하면서 이미 많은 도메인 정보를 캐싱해 둔다. 실제로 대부분의 DNS 요청은 여기서 끝난다.
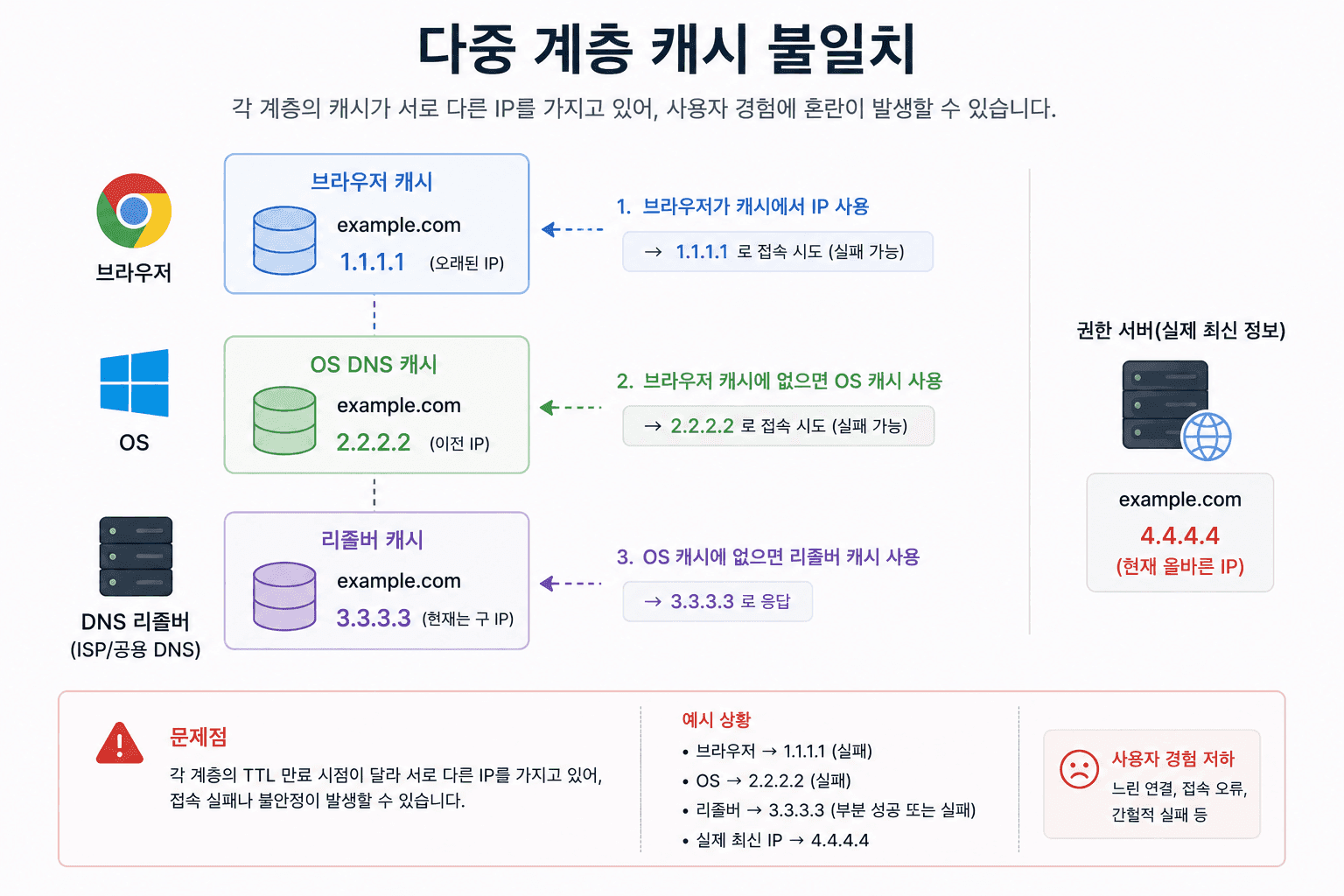
왜 문제가 발생할까? 여러 단계에 캐시가 존재하다 보니, 각 계층의 상태가 서로 다를 수 있다. 예를 들어
- 나는 브라우저 캐시가 남아 있어서 정상 접속
- 다른 사람은 캐시가 없어서 NXDOMAIN 발생
또는
- 내 PC는 OS 캐시에 옛날 IP가 남아 있음
- 리졸버는 이미 새로운 IP를 알고 있음
이처럼 캐시 불일치가 발생하면같은 도메인인데도 서로 다른 결과가 나오게 된다.
TTL: 캐시의 유효기간
이 모든 캐시는 영원히 유지되지 않는다. 각 DNS 레코드는 TTL(Time To Live)이라는 값을 가지고 있고,이 시간이 지나면 캐시는 자동으로 만료된다.
- TTL이 길면 트래픽은 줄어들지만 변경 사항이 늦게 반영된다.
- TTL이 짧으면 최신 상태는 빠르게 반영되지만 DNS 조회 비용이 증가한다.
정리하자면 DNS 캐시는 한 곳이 아니라 여러 계층에 존재한다. 브라우저, 운영체제, 리졸버. 그리고 이 구조 때문에DNS는 빠르기도 하지만, 동시에 일관성이 깨지기 쉬운 시스템이기도 하다.
NXDOMAIN과 네거티브 캐싱의 함정
DNS를 다루다 보면 가장 당황스러운 순간이 있다. 레코드를 방금 추가했는데,브라우저에서는 계속 이렇게 나온다. 설정은 분명히 맞는데, 왜 이런 일이 발생할까?
"도메인을 찾을 수 없습니다 (NXDOMAIN)"
NXDOMAIN은 무엇인가? NXDOMAIN은 네임서버가 명확하게 이렇게 답한 것이다.
"그 도메인은 존재하지 않는다"
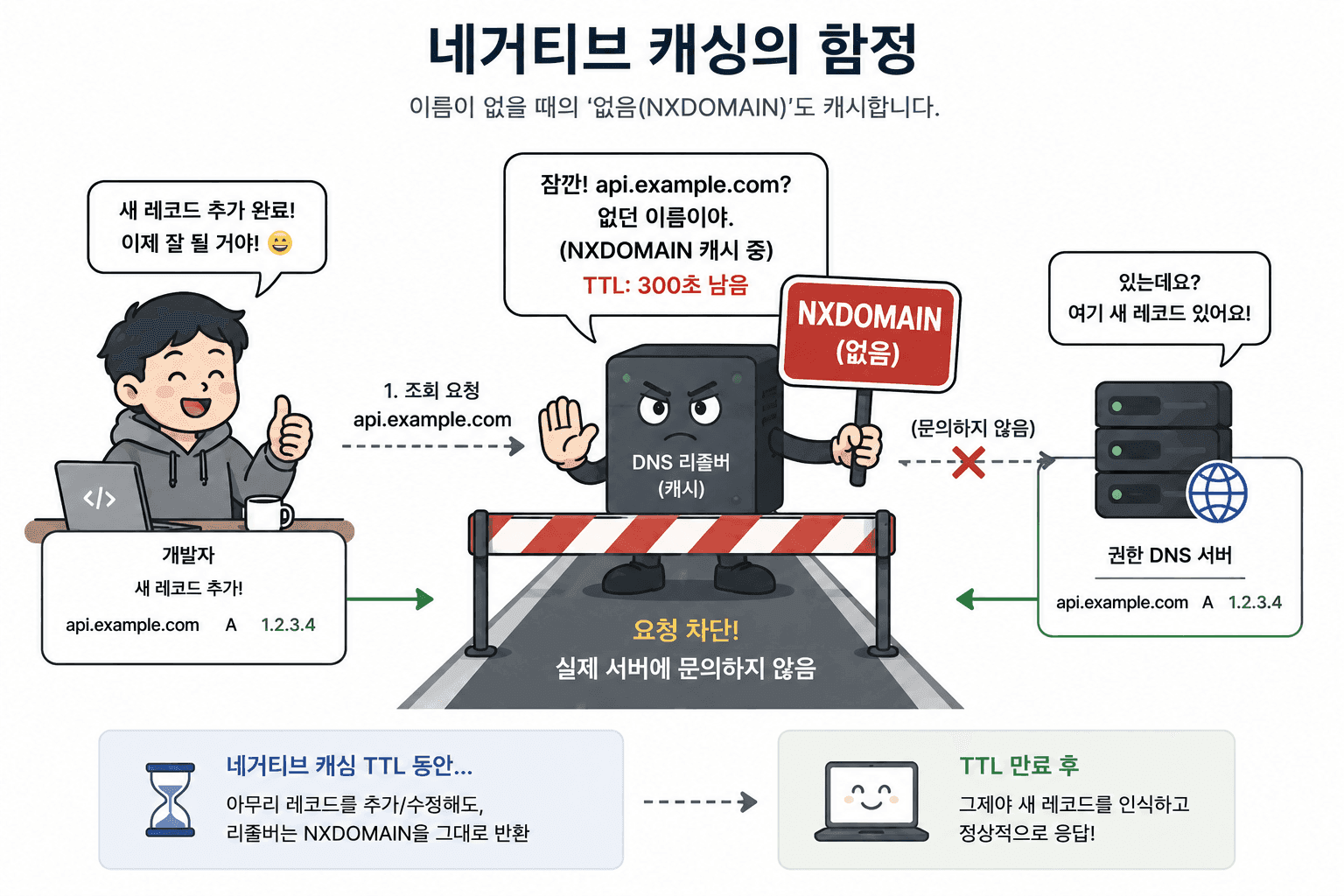
즉, 타임아웃도 아니고 서버 장애도 아니고 "확실하게 없다"는 공식 응답이다.
문제의 핵심은 네거티브 캐싱에 있다. 여기서 대부분의 혼란이 시작된다. DNS는 존재하는 도메인만 캐시하지 않는다. "존재하지 않는다"는 결과도 캐시한다. 이걸 네거티브 캐싱이라고 한다. 예를 들어
- 도메인을 조회했는데 아직 레코드가 없음
- 리졸버가 NXDOMAIN 응답을 받음
- 이 결과를 일정 시간 동안 캐시에 저장
이 상태에서 레코드를 새로 추가해도, 캐시가 살아 있는 동안은 계속 "없는 도메인"으로 인식된다.
왜 이렇게 설계되어 있을까?
이유는 단순하다. 존재하지 않는 도메인에 대해 매번 루트부터 다시 조회하면 불필요한 트래픽이 폭발적으로 증가하기 때문이다. 그래서 DNS는"없다"는 결과조차도 캐싱해서 시스템 전체 부하를 줄인다.
TTL은 어디서 결정될까?
이 네거티브 캐시의 유지 시간(TTL)은클라이언트가 임의로 정하는 것이 아니다. 도메인의 SOA(Start of Authority) 레코드에 정의된 값에 따라 결정된다. 정확히는 SOA 레코드의 TTL과 SOA 내부의 MINIMUM 값 중 더 작은 값이 사용된다. 그래서 TTL이 길게 설정된 경우레코드를 추가해도 반영이 늦어질 수 있다. 이 상황을 만나면 순서대로 확인하는 것이 중요하다.
- 로컬 캐시 제거 (브라우저 재시작, OS DNS 캐시 flush)
- 리졸버 우회 확인 (
dig나nslookup으로 권한 있는 네임서버에 직접 질의) - 상태 코드 확인(NXDOMAIN: 도메인 자체 없음, NOERROR + 빈 응답: 레코드만 없음 (NODATA))
이 과정을 거치면"설정 문제인지, 캐시 문제인지"를 명확히 구분할 수 있다. 정리하자면, NXDOMAIN은 단순한 에러가 아니라"도메인이 존재하지 않는다"는 확정 응답이다. 그리고 이 결과는 네트워크 효율을 위해캐시에 저장된다.이 네거티브 캐싱 때문에DNS는 변경 직후에도 일정 시간 동안"틀린 상태가 유지되는 것처럼 보이는" 특성을 가진다.
DNS는 어떻게 웹 성능을 무너뜨리는가
웹 성능을 이야기할 때,우리는 보통 서버 응답 속도나 렌더링 최적화에 집중한다. 하지만 그 전에 반드시 거쳐야 하는 단계가 하나 있다. 바로 DNS 조회다. 이 단계는 단순한 준비 과정이 아니라,이후 모든 과정의 시작 시점을 결정하는 출발선이다.
모든 것은 DNS 이후에 시작된다. 브라우저가 서버와 통신하기 위해서는가장 먼저 도메인을 IP 주소로 변환해야 한다. 이 과정이 끝나기 전까지는 TCP 연결도 시작할 수 없고, TLS 협상도 진행할 수 없으며, HTTP 요청도 전송할 수 없다. 즉, DNS는 네트워크 파이프라인의 가장 앞단에서 모든 것을 대기시키는 구조를 가진다.
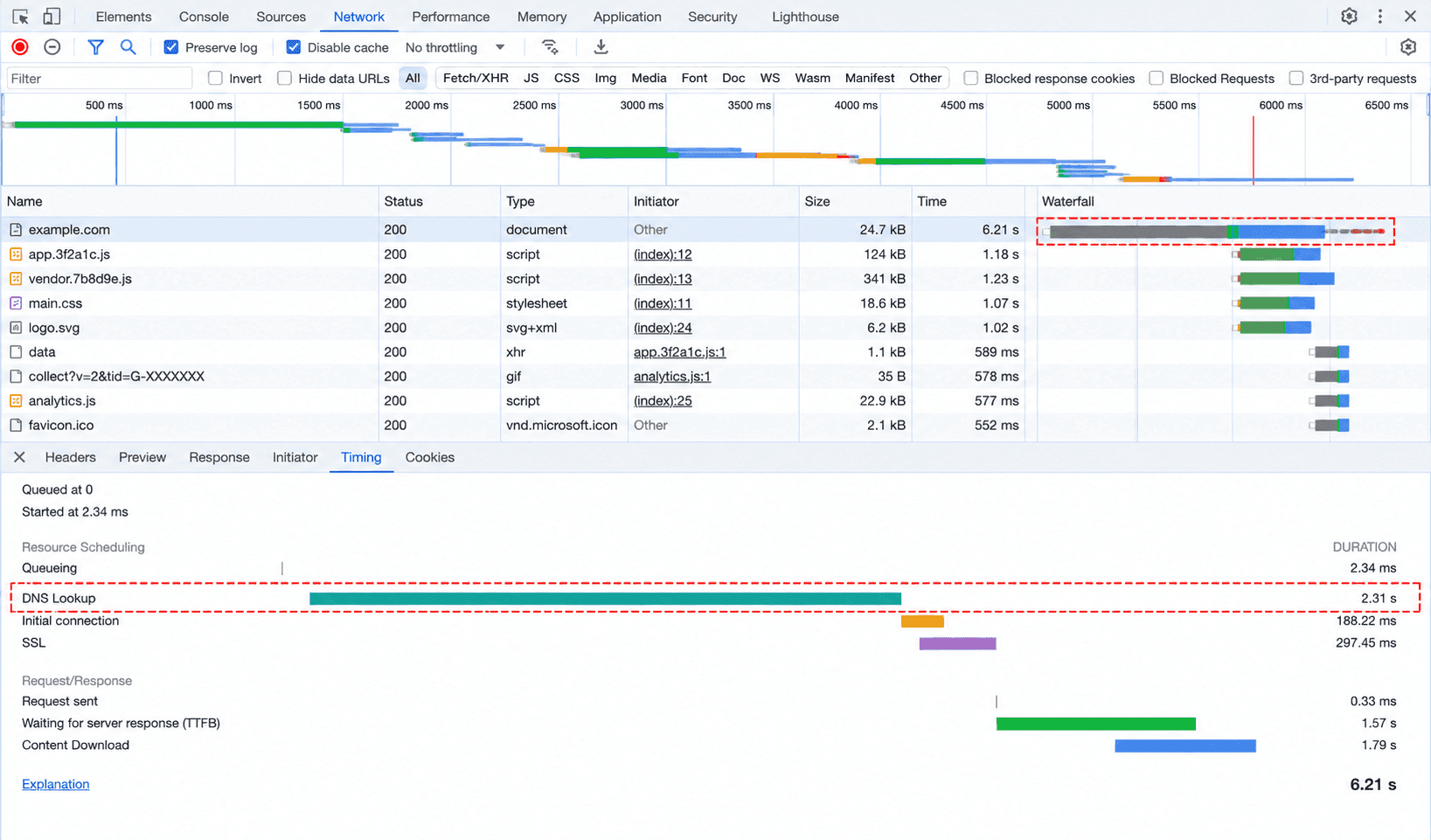
한 번의 지연이 전체를 밀어낸다. DNS 조회가 느려지면 어떤 일이 벌어질까? 이 지연은 단순히 "추가된 시간"이 아니다. 그 이후의 모든 과정이 함께 늦어진다.
- TCP 연결 시작 지연
- TLS 핸드셰이크 지연
- HTTP 요청 지연
결과적으로 서버로부터 첫 응답을 받는 시점까지모든 흐름이 뒤로 밀리게 된다. 이렇게 시작이 늦어지면,브라우저가 HTML을 파싱하고 화면을 그리는 시점 역시 자연스럽게 늦어진다.
문제는 여기서 끝나지 않는다. 초기 HTML을 받은 이후에도 브라우저는 추가적인 리소스를 계속 요청한다.
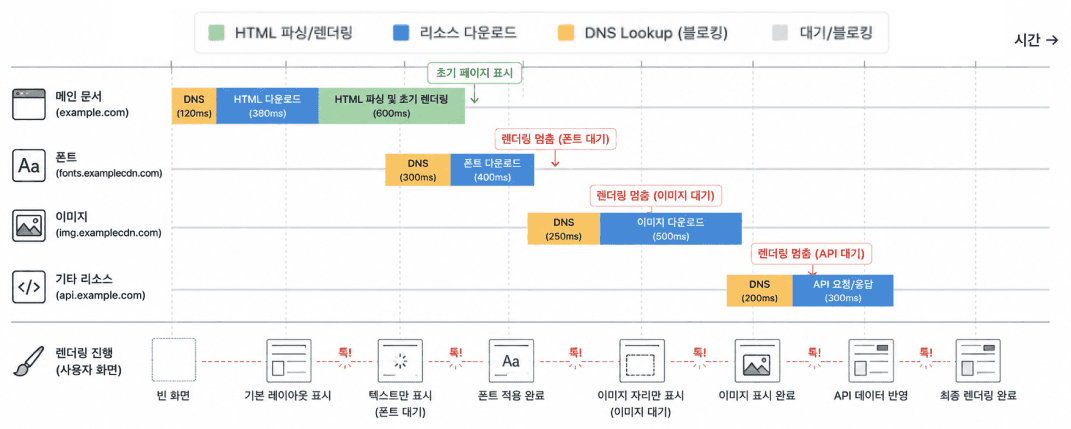
예를 들어 이미지 (CDN), 폰트 서버, 외부 스크립트. 이 리소스들이 서로 다른 도메인에 있다면,각각에 대해 새로운 DNS 조회가 발생한다. 이때의 지연은 더 치명적이다. 이미 렌더링이 진행되고 있는 중간에추가 대기 시간이 끼어들기 때문이다. 그 결과 주요 이미지 로딩이 늦어지고, 화면 완성이 지연되며, 사용자가 체감하는 속도는 크게 떨어진다.
왜 체감 성능에 더 크게 영향을 줄까? DNS는 다음과 같은 특징을 가진다.
- 항상 요청의 맨 앞에서 발생한다.
- 캐시 상태에 따라 속도가 크게 달라진다.
- 외부 네트워크 상태에 영향을 받는다.
즉, 예측하기 어렵고 통제하기 힘든 영역이면서성능에는 가장 먼저 영향을 준다. DNS 단계에서 발생한 지연은 TCP, TLS, HTTP, 그리고 렌더링까지 모든 과정에 연쇄적으로 영향을 준다. 특히 여러 도메인을 사용하는 현대 웹 환경에서는DNS 조회가 반복되면서성능 저하가 더욱 두드러진다. 결국 DNS는 웹 성능을 좌우하는 가장 작은 단위이자,가장 앞단에 위치한 첫 번째 병목 지점이다.
최신 네트워크 변화가 바꾼 것들
DNS와 네트워크 성능은 오랫동안 트레이드오프 관계였다. 보안을 강화하면 느려지고,속도를 올리면 보안이 약해지는 구조였다. 하지만 최근에는 이 흐름이 바뀌고 있다.
QUIC: 연결 자체를 빠르게 만든다
기존에는 TCP 연결과 TLS 협상이 따로 이루어졌기 때문에 연결을 시작하는 데 여러 번의 왕복(RTT)이 필요했다. QUIC은 이 과정을 하나로 합쳐최초 연결 지연을 크게 줄였다. 결과적으로, DNS 이후 이어지는 연결 단계가 훨씬 빨라졌다.
HTTPS RR: "미리 알려주는 DNS"
예전에는 브라우저가"이 서버가 HTTP/3를 지원하는지"조차 모른 채 연결을 시도해야 했다. HTTPS 레코드는 DNS 단계에서이 정보를 미리 전달한다. 덕분에 브라우저는 연결 전에 서버의 지원 프로토콜 정보를 미리 파악할 수 있게 되었고, 이를 통해 일부 재시도 비용을 줄일 수 있게 되었다.
ECH: 프라이버시까지 DNS에서 시작된다
기존에는 암호화 통신을 하더라도 접속하려는 도메인 이름(SNI)은 노출되는 문제가 있었다. ECH는 이 정보까지 암호화함으로써DNS 이후의 연결 과정에서도 프라이버시를 보호한다.
최신 네트워크 기술들은 공통적으로 DNS 이후의 연결 과정을 더 빠르고, 더 안전하게 만드는 방향으로 발전하고 있다. 즉, DNS는 단순한 "시작 단계"가 아니라,연결 방식 자체를 결정하는 출발점으로 진화하고 있다.
프론트엔드에서 DNS를 최적화하는 방법
지금까지 본 것처럼 DNS는페이지 로딩과 사용자 경험에 직접적인 영향을 준다. 그렇다면 프론트엔드에서이 DNS 지연을 줄일 수 있는 방법은 없을까? 완전히 없애는 것은 불가능하지만,브라우저의 동작을 앞당기는 방식으로 충분히 개선할 수 있다.
핵심 아이디어는 "미리 해두기"로 DNS 최적화의 핵심은 단순하다. "필요해지기 전에 먼저 해둔다" 브라우저가 리소스를 실제로 요청하기 전에DNS 조회나 연결을 미리 시작하게 만드는 것이다. 이를 위해 사용하는 것이 리소스 힌트(Resource Hints)다.
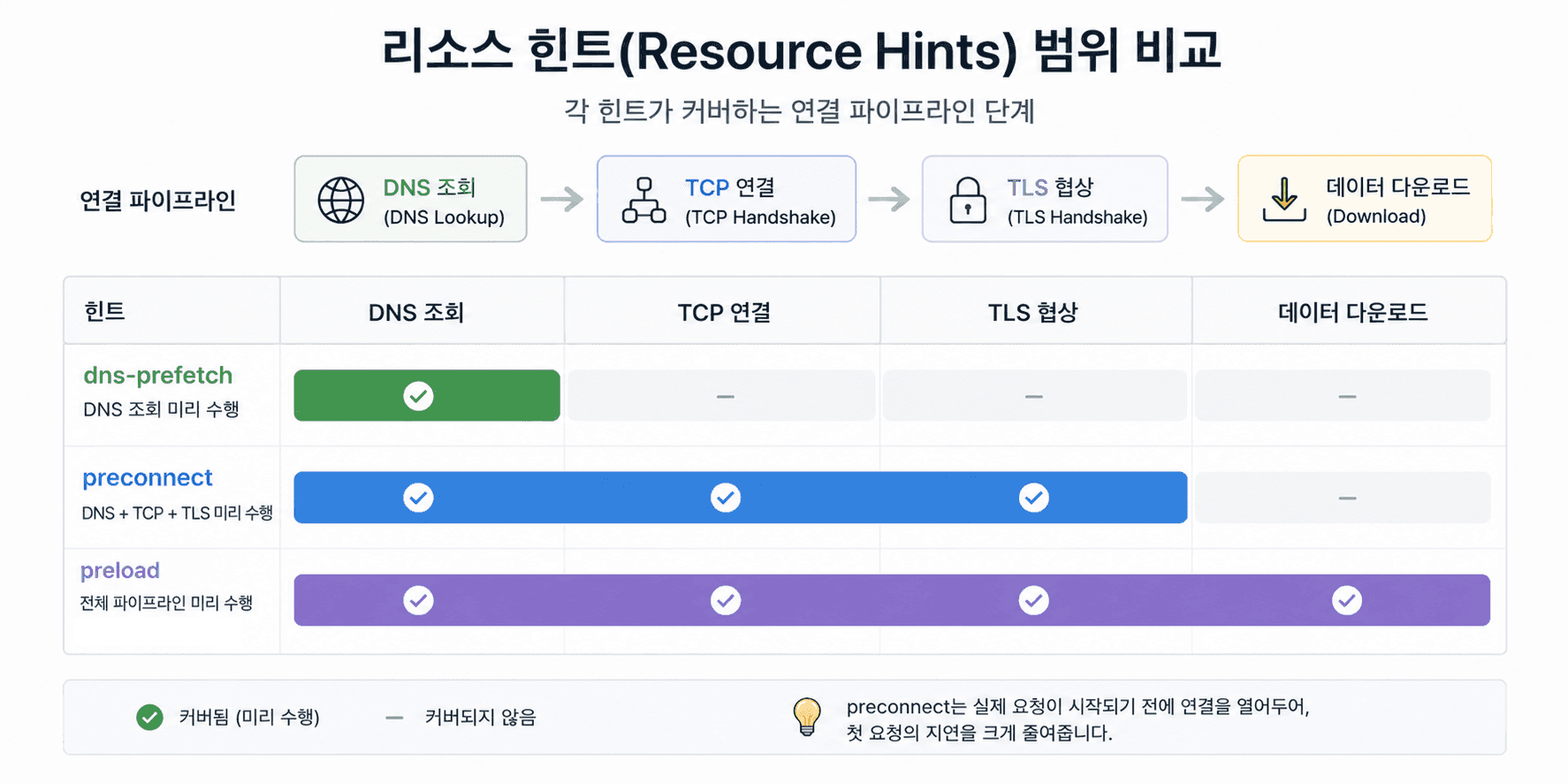
1. dns-prefetch: 가장 가볍게 시작하기
dns-prefetch는 말 그대로DNS 조회만 미리 수행한다.
<link rel="dns-prefetch" href="//cdn.example.com"
이렇게 설정하면,브라우저는 해당 도메인의 IP를 미리 알아둔다. 이후 실제 요청이 발생할 때 DNS 단계가 이미 끝난 상태로 시작된다.
2. preconnect: 연결까지 미리 준비
preconnect는 한 단계 더 나아간다. DNS 조회, TCP 연결, TLS 이 모든 과정을 미리 끝내고 사용 가능한 연결을 대기 상태로 만들어 둔다.
<link rel="preconnect" href="<https://cdn.example.com>">
특히 다음과 같은 경우 효과적이다:
- 폰트 서버
- 주요 CDN
- 초기 렌더링에 필요한 외부 리소스
3. preload: 아예 먼저 다운로드
preload는 DNS 자체를 줄이는 기능은 아니지만, 리소스 로딩 시작 시점을 앞당겨 전체 렌더링 지연을 줄이는 데 사용된다. preload는 DNS를 넘어서 리소스 자체를 즉시 다운로드하도록 지시한다.
<link rel="preload" href="/main.css" as="style">
렌더링에 반드시 필요한 리소스에만 사용해야 한다
언제 써야 할까?
리소스 힌트는 아무 곳에나 쓰는 게 아니다. 효과가 큰 지점은 명확하다.
- 초기 렌더링에 꼭 필요한 외부 도메인
- LCP 요소가 위치한 CDN
- 폰트, 핵심 이미지 서버
이런 곳에 제한적으로 사용해야 한다. 가장 흔한 실수로는 리소스 힌트는 강력하지만, 잘못 쓰면 오히려 성능을 떨어뜨린다. 대표적인 실수는 다음과 같다.
- 너무 많은 도메인에 dns-prefetch 남발
- preconnect를 여러 개 걸어 소켓 낭비
- 실제로 사용하지 않는 리소스를 preload
이 경우 브라우저는불필요한 네트워크 작업을 먼저 수행하게 되고, 오히려 중요한 요청이 늦어질 수 있다.프론트엔드에서 DNS를 최적화하는 방법은"브라우저보다 한 발 앞서 움직이는 것"이다.
- dns-prefetch: DNS만 미리
- preconnect: 연결까지 미리
- preload: 리소스까지 미리
이 세 가지를 적절히 사용하면DNS로 인한 초기 지연을 상당 부분 줄일 수 있다. 다만 중요한 건 "많이"가 아니라"정확한 곳에만" 사용하는 것이다.
백엔드에서 DNS가 병목이 되는 순간 (Node.js)
프론트엔드에서는 DNS가 "지연 요소"로 보이지만, 백엔드에서는 상황이 더 심각해질 수 있다. 특히 Node.js 환경에서는DNS가 단순한 네트워크 비용을 넘어 서버 전체를 멈추게 만드는 병목이 되기도 한다.
겉보기와 다른 dns.lookup의 정체
Node.js에서 외부 API를 호출할 때,우리는 보통 이런 코드를 자연스럽게 사용한다.
- axios ,fetch, http/https 모듈
이 내부에서는 도메인을 IP로 변환하기 위해dns.lookup()이 호출된다. dns.lookup 자체는 JavaScript 레벨에서는 비동기로 동작하지만, 내부적으로는 OS의 getaddrinfo 기반 조회를 libuv 스레드 풀에 위임한다. 따라서 DNS 응답이 느려질 경우 제한된 스레드 풀이 포화되면서 전체 처리량 저하로 이어질 수 있다.
libuv 스레드 풀 병목
Node.js는 이 문제를 피하기 위해이 작업을 백그라운드 스레드 풀(libuv)로 넘긴다. 그런데 여기서 치명적인 제약이 있다. 기본 스레드 풀 크기는 단 4개다. 이 말은 즉, 동시에 최대 4개의 DNS 조회만 처리 가능하고 나머지는 큐에서 대기라는 의미다.
실제로 벌어지는 문제로 예를들어 여러 외부 API를 동시에 호출하거나 다양한 도메인으로 요청이 몰리는 상황에서 DNS 응답이 느려지면이 4개의 스레드가 전부 점유된다. 그 결과 아래 작업들까지 모두 대기 상태에 빠진다.
- 파일 I/O
- 암호화 작업
- 기타 비동기 작업
즉, DNS 하나 때문에 서버 전체 처리량이 급격히 떨어지는 상황이 발생한다.더 큰 문제는 캐시가 없다는 것이다. 브라우저와 달리,Node.js 런타임에는 기본 DNS 캐시가 없다. 즉, 같은 도메인을 수백 번 요청하더라도매번 OS를 통해 DNS 조회가 반복된다. 이 구조는 트래픽이 늘어날수록병목을 더 빠르게 악화시킨다.
어떻게 해결할 수 있을까? 이 문제는 단순 튜닝이 아니라,설계 관점에서 접근해야 한다.
1. 애플리케이션 레벨 캐싱
가장 현실적인 방법은DNS 결과를 직접 캐싱하는 것이다. LRU 캐시나 TTL 기반 캐시를 통해 불필요한 DNS 조회를 줄일 수 있다.
2. dns.resolve 계열 사용
dns.resolve 계열은 OS의 getaddrinfo를 사용하지 않고,DNS 프로토콜 기반 조회를 수행하기 때문에 libuv 스레드 풀 병목 영향을 받지 않는다.
3. 연결 재사용 (Keep-Alive)
HTTP 연결을 재사용하면 DNS 조회 자체가 반복되지 않는다. keep-alive, connection pooling 이 설정만으로도DNS 호출 횟수를 크게 줄일 수 있다. 정리하자면 Node.js에서 DNS는 단순한 네트워크 비용이 아니다.
dns.lookup→ 사실상 동기 작업- libuv 스레드 풀 → 제한된 자원
- 캐시 없음 → 반복 호출
이 세 가지가 결합되면, DNS는 애플리케이션 성능을 낮추는 병목이 된다. 이 구조를 이해하고 대응해야만,고트래픽 환경에서도 안정적인 성능을 유지할 수 있다.
Reference
Image made by GPT
https://developerxdasomu.tistory.com/13
https://developer.mozilla.org/ko/docs/Glossary/DNS
https://velog.io/@yonghyeun/DNS-%EC%A1%B0%ED%9A%8C-DNS-Lookup