1. k8s 도입전까지의 생각

1. 서론
드디어 팀 프로젝트로 개발한 Vite 기반 서비스의 구현을 마무리했고, 모든 기능이 정상적으로 동작하는 상태까지 도달했다.
이후 초기 사용자 유입을 늘리기 위해 Lighthouse 지표 개선에 관심을 갖게 되었다.
점수를 올리기 위해 여러 시도를 해보았지만, 기대만큼의 개선은 이루어지지 않았고 지표는 일정 수준에서 정체되어 있었다.
물론 개선할 수 있는 방법은 더 있었겠지만, 이전 회고에서도 언급했듯이 이 부트캠프의 가장 큰 목적은 완성도보다는 경험과 학습이라고 생각했다.
특히 현직 멘토님과의 티키타카 속에서 새로운 기술과 아키텍처를 직접 설계하고 구현해보는 경험은, 부트캠프라는 환경이기에 가능하다고 느꼈다.
그래서 기존 Vite 기반 프로젝트를 Next.js로 마이그레이션하고, 트래픽 변화에 유연하게 대응할 수 있는 서비스 구조를 직접 구축해보기로 결정했다.
현재도 성능 최적화와 관련된 여러 작업을 병행하고 있으며,
우선 마이그레이션을 한 지금까지의 진행 상황은 다음과 같다.

배포 과정에서 겪은 경험에 대한 회고, 트러블 슈팅 등 많은 회고가 있지만 오늘은 리소스 설정, 인프라 관리를 위해 모니터링 해본 경험을 회고하려고 한다.
2. 고민했던 사항들 정리 AS-IS
- Nextjs의 성능 문제
원래 SSR은 api지연도 있고 html을 생성하는 작업을 수행하기 때문에 성능에 큰 영향을 준다. 이건 고질적인 문제인데, Nextjs은 TPS,RPS 지표가 매우 안좋은 프레임워크이다.
RPS 클라이언트가 서버에 1초에 몇개의 요청을 보내는지를 나타내는 지표이고 , TPS 는 초당 트렌젝션 수로 1초에 몇 개의 의미 있는 작업(트랜잭션)을 완료하는지를 나타내는 지표이다.
즉 간략히 정리하면 SEO를 위해 SSR을 도입했는데, SEO는 좋아졌지만 html을 생성하는 작업이 너무 오래걸려서 성능이 안좋아지는 문제가 있었다.
2. CPU 리소스 부족 (인프라 비용)
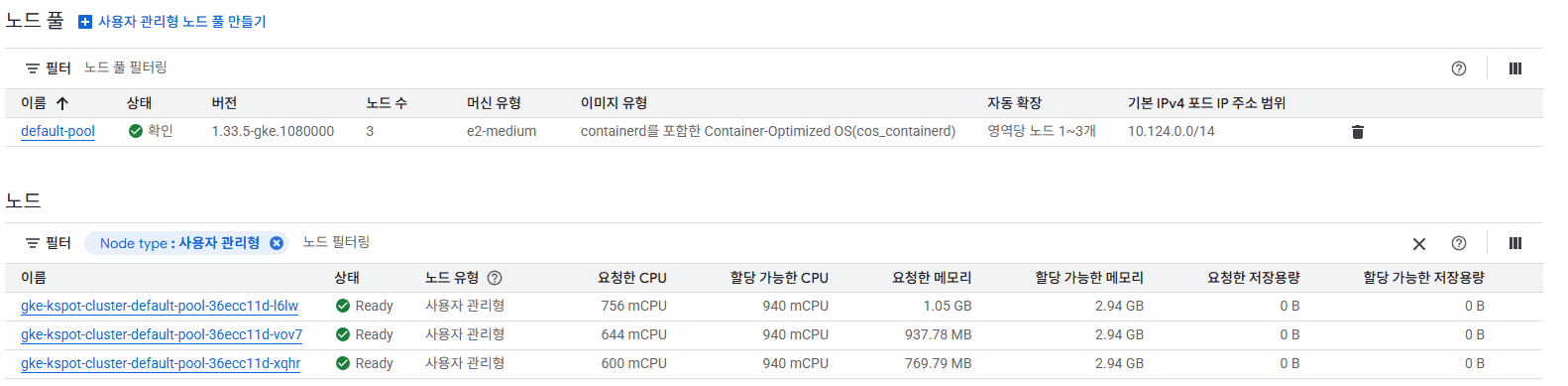
현재 상황이 gcp 쿠버네티스에 워커 노드 3개를 띄워두고 Nextjs 컨테이너를 기본 2개, 트래픽 발생시 3개 까지 늘려서 사용하고 있다. 다만 gcp에서 가장 저렴한 노드 타입을 사용중이었기 때문에 요청 가능한 CPU리소스에 한계가 있었다. 왜냐하면 k8s설정 pod들이 최소로 가져가는 CPU리소스를 제외하고 나면 내가 쓸수있는 양이 너무 적었다.
초반에 아무 생각없이 vite 코드만 옮겼을때는 당연히 기본값이 SSR이므로 CPU리소스가 날뛰는 현상이 있었고 pod들이 pending상태에 빠지는 문제가 있었다. 엔지니어링 해야겠지...?
3. 생각해보기
SSR에 갇히지 말자
AWS cloudfront에 배포해둔 vite가 빠르고 오류없이 동작하는 이유가 뭘까? 생각해보면 당연하겠지만 CSR이고 CDN에 캐싱해두었기 때문에 빠르다고 할 수 있다. 그러면 SSR이 성능이 않좋은 이유는 뭐야? 라고 생각해보면 다음과 같이 생각해 볼 수 있다.
사용자 A : 홈페이지 진입, 서버야 html좀 내려줘라.
서버 : Okay, 내가 백엔드에 직접 api호출해서 완성된 html을 뿌려줄게. 잠시만 기다려봐.
사용자 B : 홈페이지 진입, 서버야 html좀 내려줘라.
서버 : Okay, 내가 백엔드에 직접 api호출해서 완성된 html을 뿌려줄게. 잠시만 기다려봐.
사용자 C : 페이지 진입, 서버야 html좀 내려줘라.
서버 : 같은 작업만 계속 해야하네. 결국 같은 페이지인데… CPU뜨거워서 다운할래.
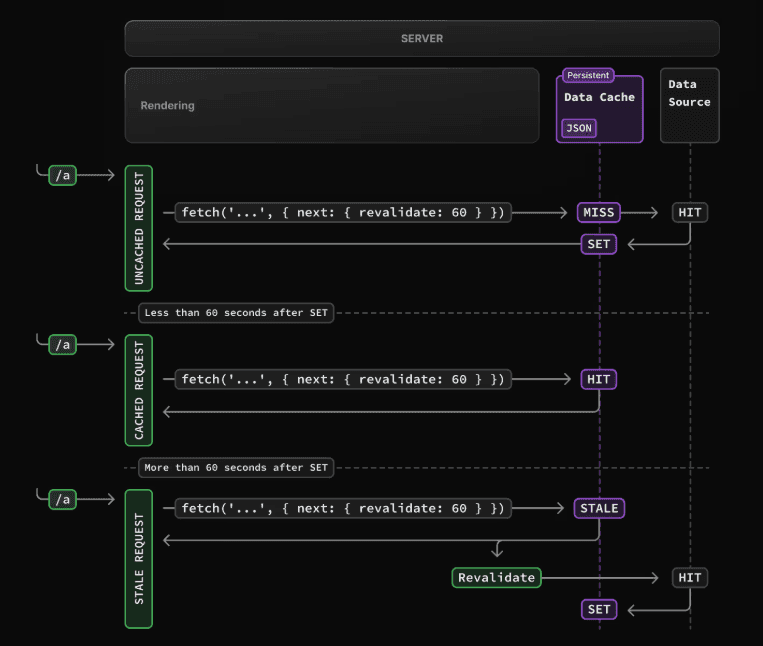
위 흐름에서 생각해볼 점은 모든 사용자가 요청할때마다 같은 html을 내려주지만 이걸 매번 수행하지 않을 방법은 없을까? 우리는 개발자이므로 하나의 방법을 생각할 수 있는데, 그건 바로 Caching 캐싱 이다.
수평적 확장과 수직적 확장
가장 간단한 방법이다.
- CPU가 부족하다고? 그럼 돈 더써서 컨테이너 수를 늘리면 되는거지!
- CPU가 부족하다고? 그럼 돈 더써서 좋은 인스턴스로 바꾸고 컨테이너의 CPU점유를 늘리면 되지!
가장 간단하지만 무슨 문제가 있을까 하면, 당연히 money 문제이다. gcp든 aws든 개발단계에서만 사용하기 좋은(사실상 학습용) 인스턴스를 standard옵션보다 저렴하게 올려두는 경우가 있다. 본인의 경우 값싼 e2 인스턴스를 사용중이고, standard옵션으로 올리는 순간 아래같은 끔찍한 상황이 생긴다.
- 보통
e2-medium보다 젤 싼e2-standard가 가격이 두배이다. 근데 나는 쿠버네티스에서 스케일링을 통해 노드를 3개까지 사용중인데 그럼 금액이x6이라는 놀라운 클라우드 비용이 청구된다.
그렇다면 노드 사양을 유지하고서도 좋은 퍼포먼스를 유지하는 방법은 무엇일까?를 고민하면 되는 문제였다.
2. SSR에서 ISR,SSG를 통한 캐싱 도입 TO-BE
vite를 마이그레이션 했을 당시엔 use client고 뭐고 모든게 SSR이었다. 당연히 CPU가 날뛰었고, 내가 생각한 방법은 Nextjs의 이점들을 활용하자 였다.
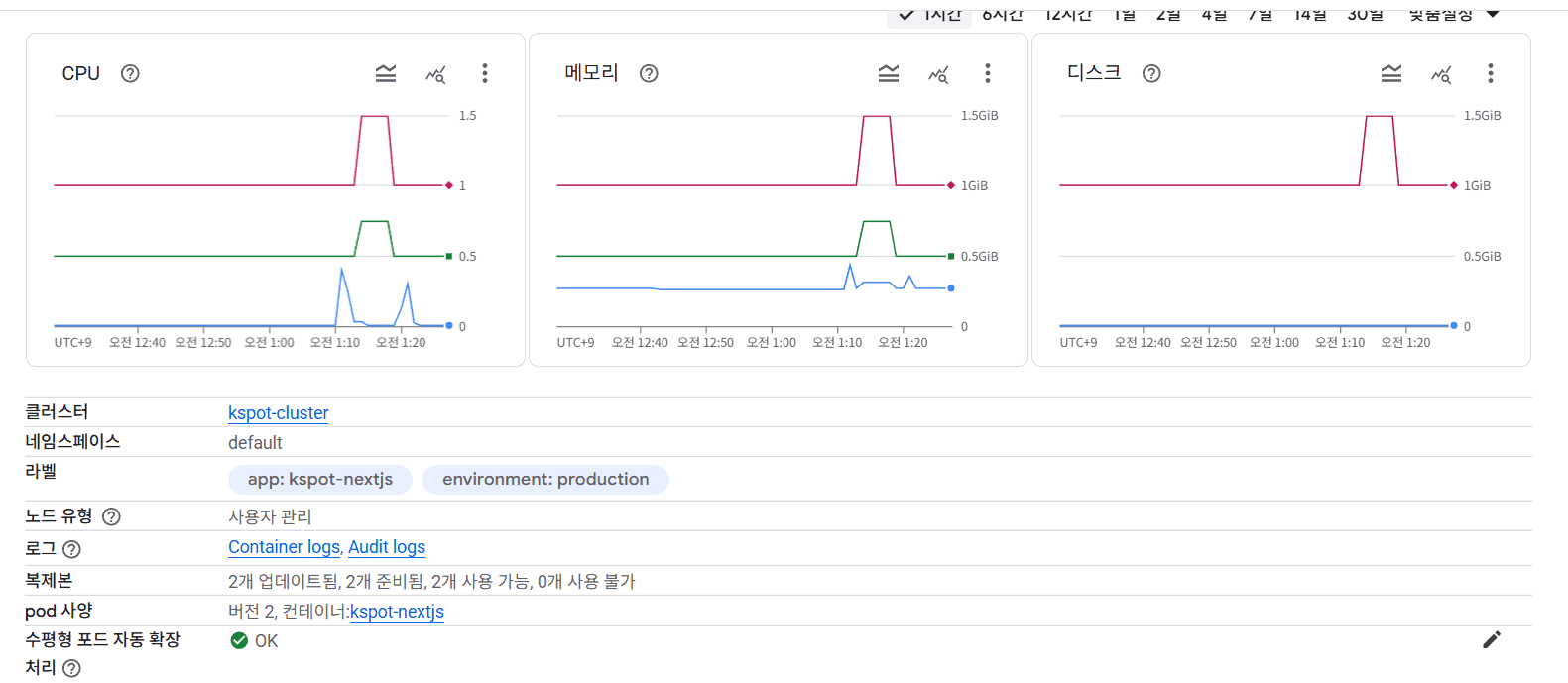
사실 우리가 다루고있는 컨텐츠들(ex: 오징어게임), 장소들(주소,설명등)은 변하기 쉽지않은 정보이다. 예를들면 우리가 사용중인 외부 api에서 갑자기 오징어게임이란 컨텐츠를 없애버리거나, 컨텐츠와 연관된 장소가 갑자기 철거되어서 없어지는 경우가 아니라면 캐싱된 데이터를 그대로 사용해도 된다고 판단했다.
따라서 페이지 랜더링 전략을 수립할 때 변하지 않을 정적인 페이지들은 빌드 시점에 캐싱해두고, 홈페이지 처럼 인기컨텐츠에 대한 바뀔수 있는 정보를 취급할때는 ISR방식으로 처리하기로 했다.
백엔드 spring에서 스케줄러로 tmdb api를 업데이트하는 주기는 하루이므로, revalidate 주기를 하루로 설정하면 깔끔하다 생각했다.
캐싱을 적용하고 페이지 접속해보니, 당연히 아무리 요청을 해도 캐싱된 페이지들이 보였으므로 lighthouse지표는 물론 SSR당시 느리게 로드되던 이미지들도 빠르게 로딩되는 것을 확인할 수 있었다.
3. 모니터링을 통해 k8s pod당 점유하는 CPU를 최소화 해보자
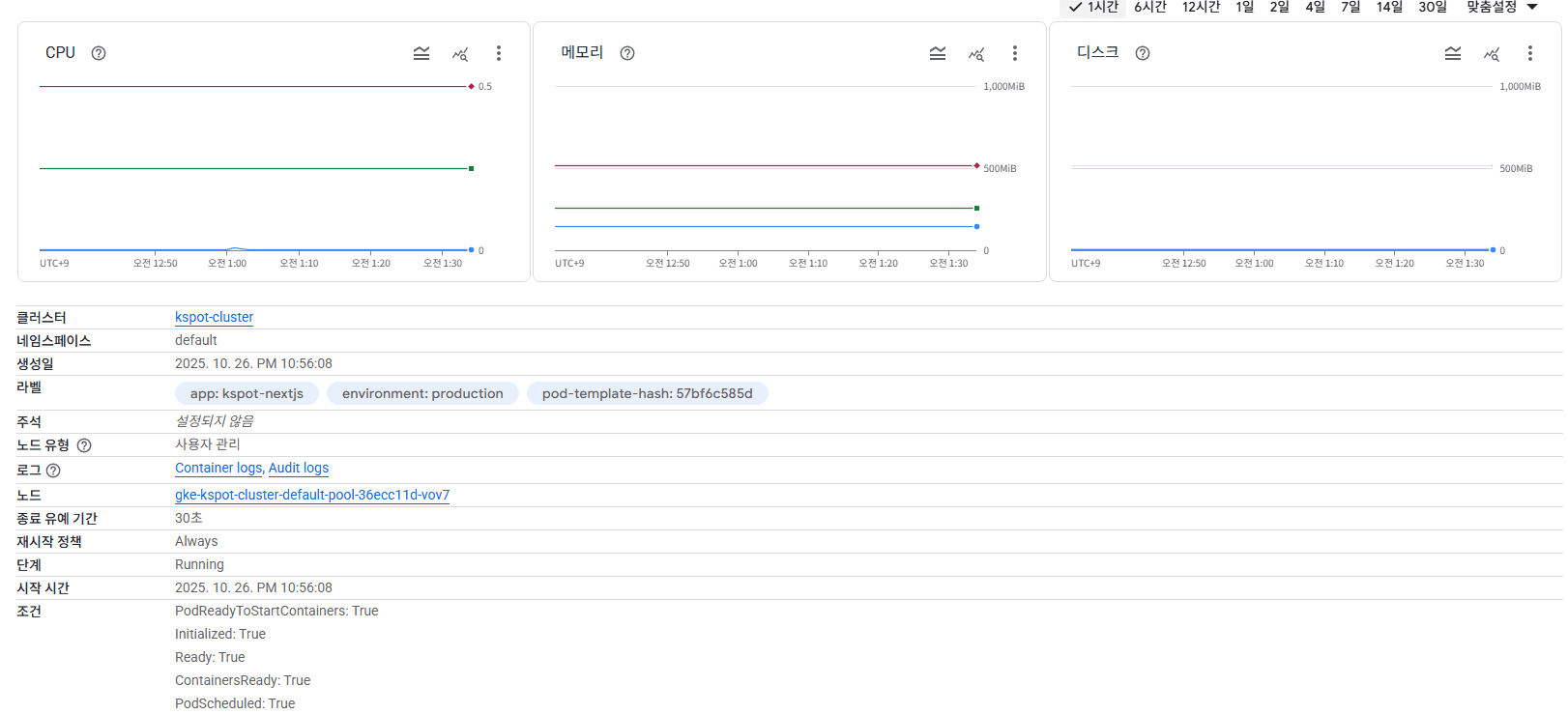
현재 NExtjs pod에 할당해둔 CPU는 아래같이 설정해두었다.
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"근데 문제가 무엇이냐? 가장 저렴한 노드를 사용중이므로 k8s 설정pod들을 감당하기도 어려웠기 때문에 공간이 매우 부족했었다.

위에서 언급했던 대로 좋은 비싼 인스턴스로 바꾸는 방법은 있지만, 이러면 엔지니어가 아니지 않나? 사실 위 이미지는 캐싱을 적용하기 전 노드 상황이고, 캐싱을 적용했으니 성능측정을 통한 k8s pod설정을 변경해주어야한다. 인스턴스 사양은 유지하면서 CPU점유율을 낮추어서 급증하는 트래픽에도 어느정도 대응하는 서비스임을 모니터링해보자.
1. K6 와 VPA를 활용한 트래픽 모니터링
목표 : 250m을 점유하고 있는 pod의 점유율을 낮추자.
K6는 Grafana에서 만든 kubernetss부하 테스트를 위한 프로그램이다.
스크립트 작성
- VPA addon활성화, K6 설치
gcloud container clusters update kspot-cluster \
--enable-vertical-pod-autoscaling \
--zone asia-northeast3-a
choco install k6- K6 스크립트 작성
- 총 25분 테스트로 처음엔 50명의 트래픽까지 부하를 진행하고, 10분간 50명을 유지한다.
- 100명까지 사용자를 증가시키고, 5분간 유지한다.
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate } from 'k6/metrics';
const errorRate = new Rate('errors');
export const options = {
stages: [
{ duration: '5m', target: 50 },
{ duration: '10m', target: 50 },
{ duration: '3m', target: 100 },
{ duration: '5m', target: 100 },
{ duration: '2m', target: 0 },
],
thresholds: {
http_req_duration: ['p(95)<2000'],
errors: ['rate<0.05'],
http_reqs: ['rate>10'],
},
};
...
2. 50명 부하시점에 테스트를 모니터링해보자
아무런 요청이 없을땐 CPU 사용량은 15m이다. ****17분쯤 지표로 50명을 계속 유지하고 있을때와 gcp에서 확인해본 pod의 부하량이다. 50명을 유지할때는 pod당 CPU실 사용량이 60m정도로 사용되는것을 확인했다.
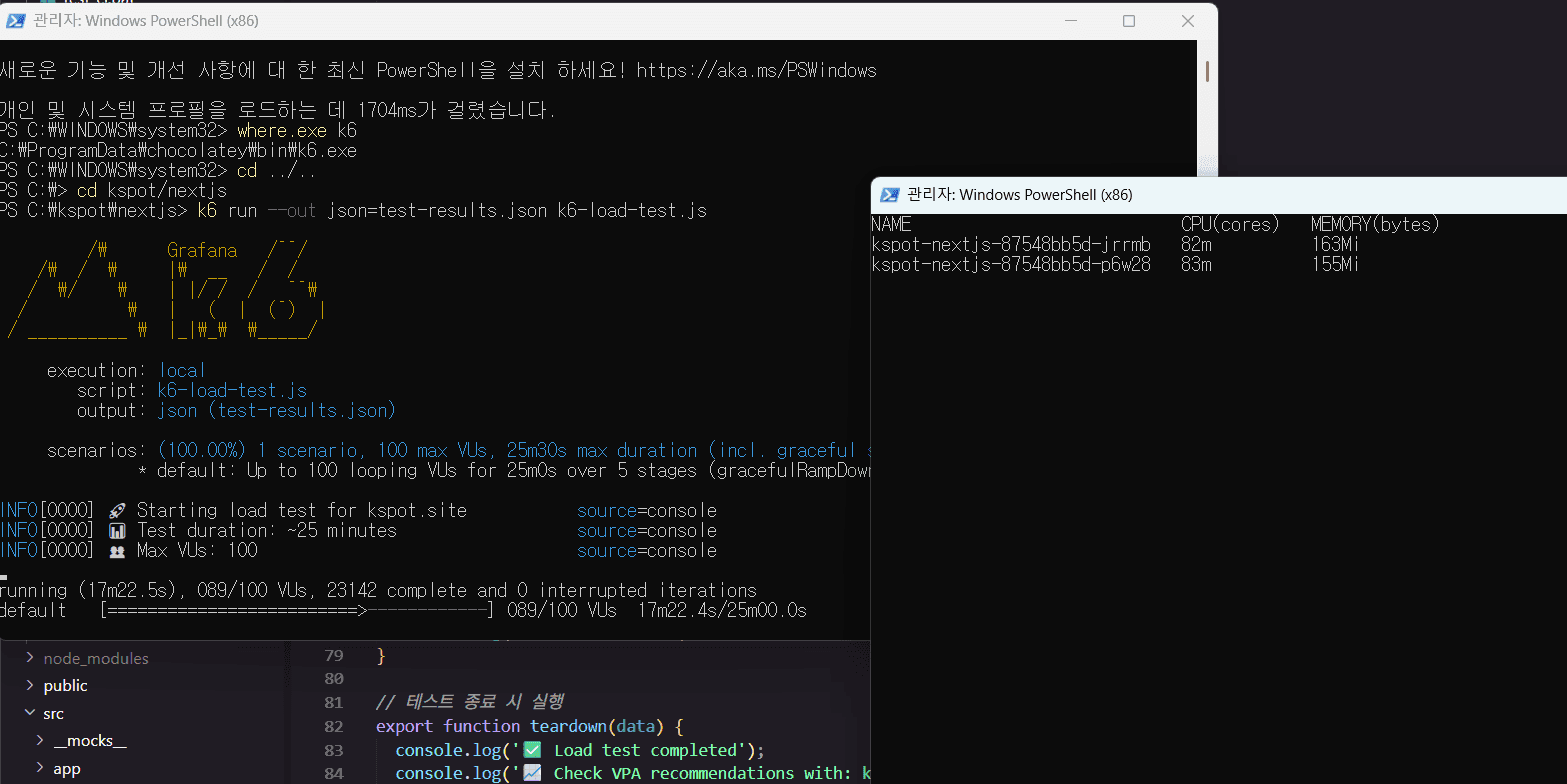
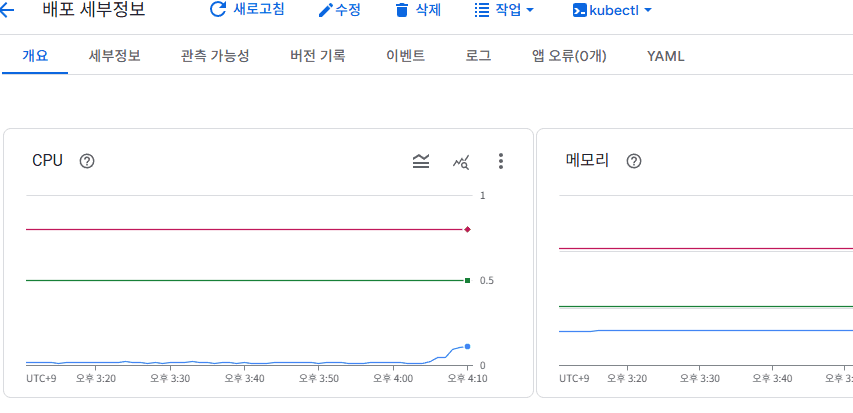
아무런 요청이 없을땐 CPU 사용량은 15m이다. ****17분쯤 지표로 50명을 계속 유지하고 있을때와 gcp에서 확인해본 pod의 부하량이다. 50명을 유지할때는 pod당 CPU실 사용량이 60m정도로 사용되는것을 확인했다.
3. 급증한 트래픽 100명
확실히 100명이 동접 해서 요청을 계속 날리면 CPU가 100m이 넘어가는걸 확인할 수 있었다.
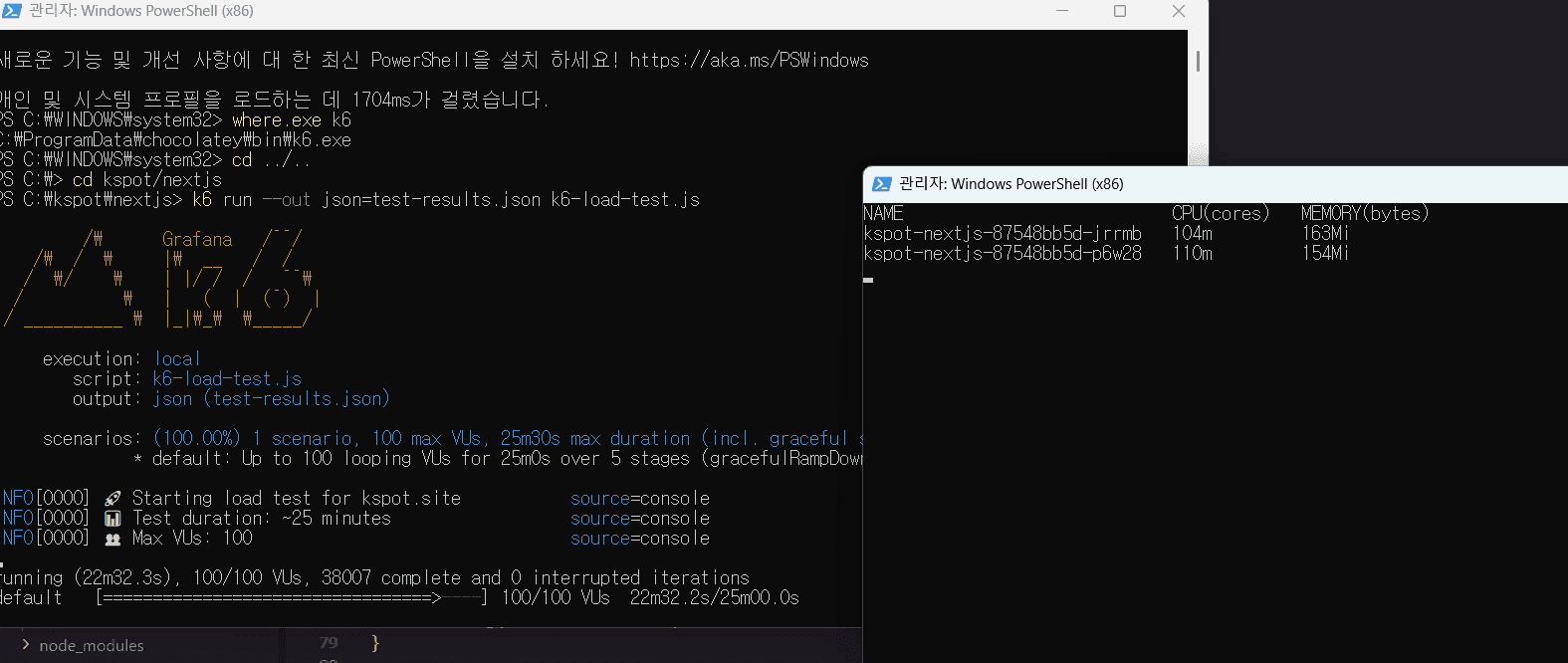
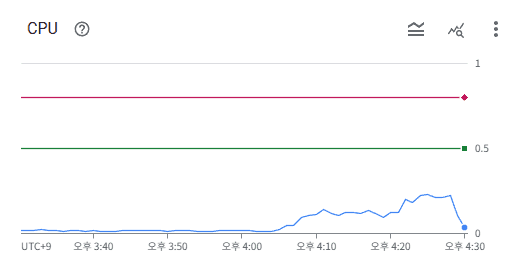
4. 테스트 결과, 리소스 절약 TO-BE
테스트 결과
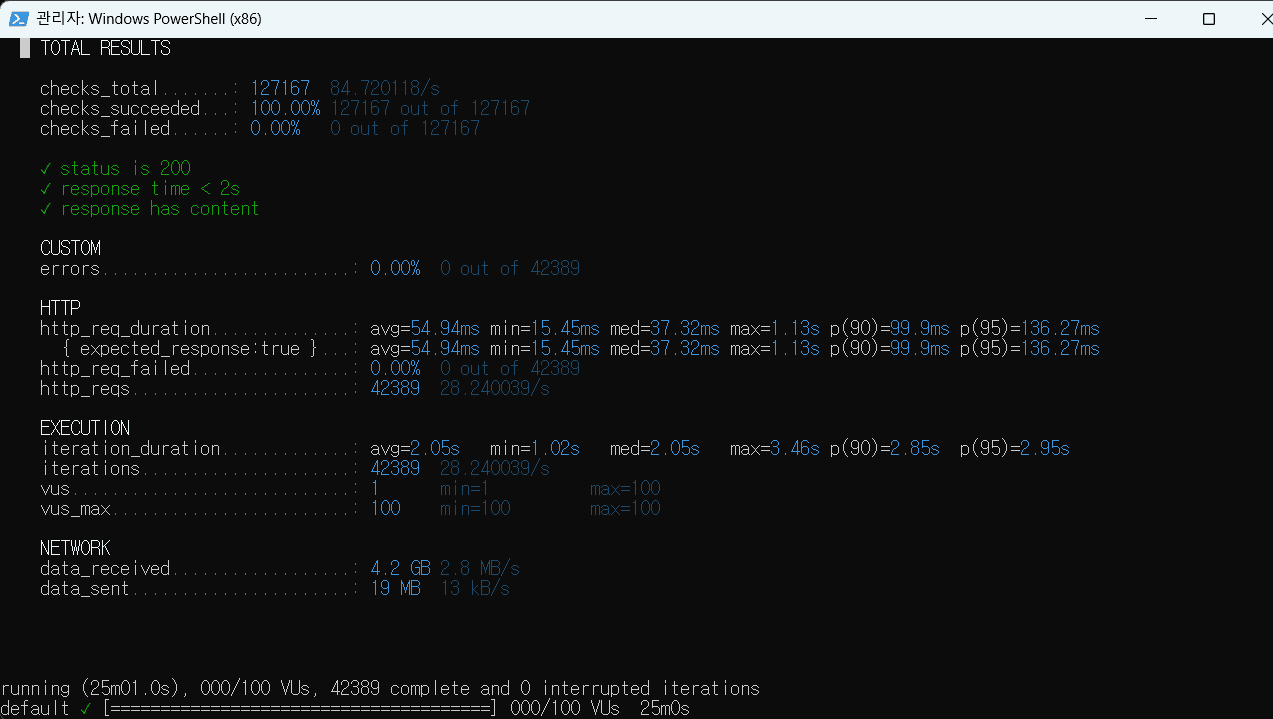
- 총 42,389번의 HTTP 요청이 25분 동안 성공적으로 완료되었으며, 초당 약 28.24 요청을 처리했다.
- 모든 요청(100%)이 HTTP 200 응답을 받았고, 응답 시간은 모두 2초 미만으로 양호했다.
- 평균 HTTP 요청 응답 시간은 54.94ms였으며, 95%의 요청이 136.27ms 이내에 응답했다.
- 테스트는 100명의 가상 사용자(VUs)를 사용하여 실행되었으며, 네트워크를 통해 약 4.2GB의 데이터를 수신했다.
VPA의 리소스 할당량 추천 : 모니터링 용도이므로, hpa.yml 과의 충돌가능성을 제외하고자 아래 옵션을 사용하고있다. 30분뒤에 측정한 결과에 cpu리소를 100m으로 추천해서 잘못된건가 생각했지만 대충 캐싱된 데이터만 사용해서 응답하는 경우가 많았고, 결국 수평확장하니 괜찮은 설정이다라는 결론을 얻을 수 있었다.
updatePolicy:
updateMode: "Off" 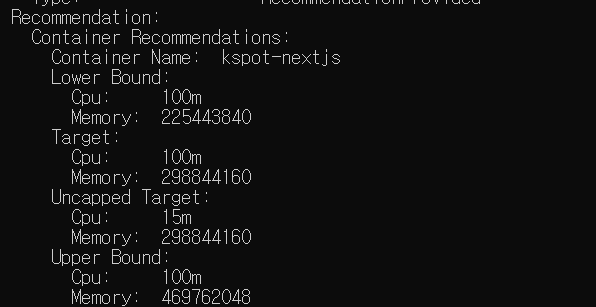
그래도 안전안전하게 점유 CPU (requests)설정을 170m으로 두고, limits를 300m 으로 설정하여 기존보단 pod당 80m의 리소스를 절약할 수 있었고, 아래같은 안정적인 운영을 할 수 있게 되었다.